



This blog has been sleepy for the past few months, but I did put out a feelings post on MIT Admissions in January, if you want more feelings-flavored text. This post… includes more technical content than most posts, but there’s also some thoughts in it.
For the past few months, I’ve been quietly spinning this thought around in the back of my mind, about what I learned from the MEng. I’m quite happy with many of the concrete things I got out of it: I got to TA a couple of classes, which was ultimately very rewarding; I got to deep dive into a research topic and get an okay sense of what being a graduate student is like, especially during the summer; and I got to spend a little more time in the MIT bubble, taking more classes, making use of the resources (particularly in the arts), and spending more time with friends. With a bit of distance, I can look back on it and firmly say that it was worthwhile and that I would do it again, even if I found some parts of it rather thorny and difficult.
Still, beyond just the technical details of all the computer architecture and operating systems stuff I learned, I’ve been wondering if there’s something bigger picture that I got out of the MEng, and over time—and especially as I’ve started getting really deep into my new job—I think the one big thing that has really crystallized for me is this feeling of “be not afraid.”
We’ll start from the concrete example in the MEng, and build to some more general ideas. My MEng thesis was on hardware acceleration for FPGA routing.1 In practice, what this meant was taking an existing implementation of FPGA routing, called Verilog-to-Routing (VTR), and porting it to run on a hardware accelerator called Swarm. Swarm has a somewhat different execution model from a traditional CPU that makes it better at exploiting irregular parallelism.2
Both of these systems are incredibly complicated on their own, and in order to make forward progress, I needed to understand it all. On the VTR side, I needed to understand how FPGA routing works at an algorithmic level, and how the implementation works at the level of C++. On the Swarm side, I needed to understand the execution model of the accelerator, how it executed programs at an assembly level, and, since our implementation of Swarm was simulated, how the simulator worked at a code level as well.
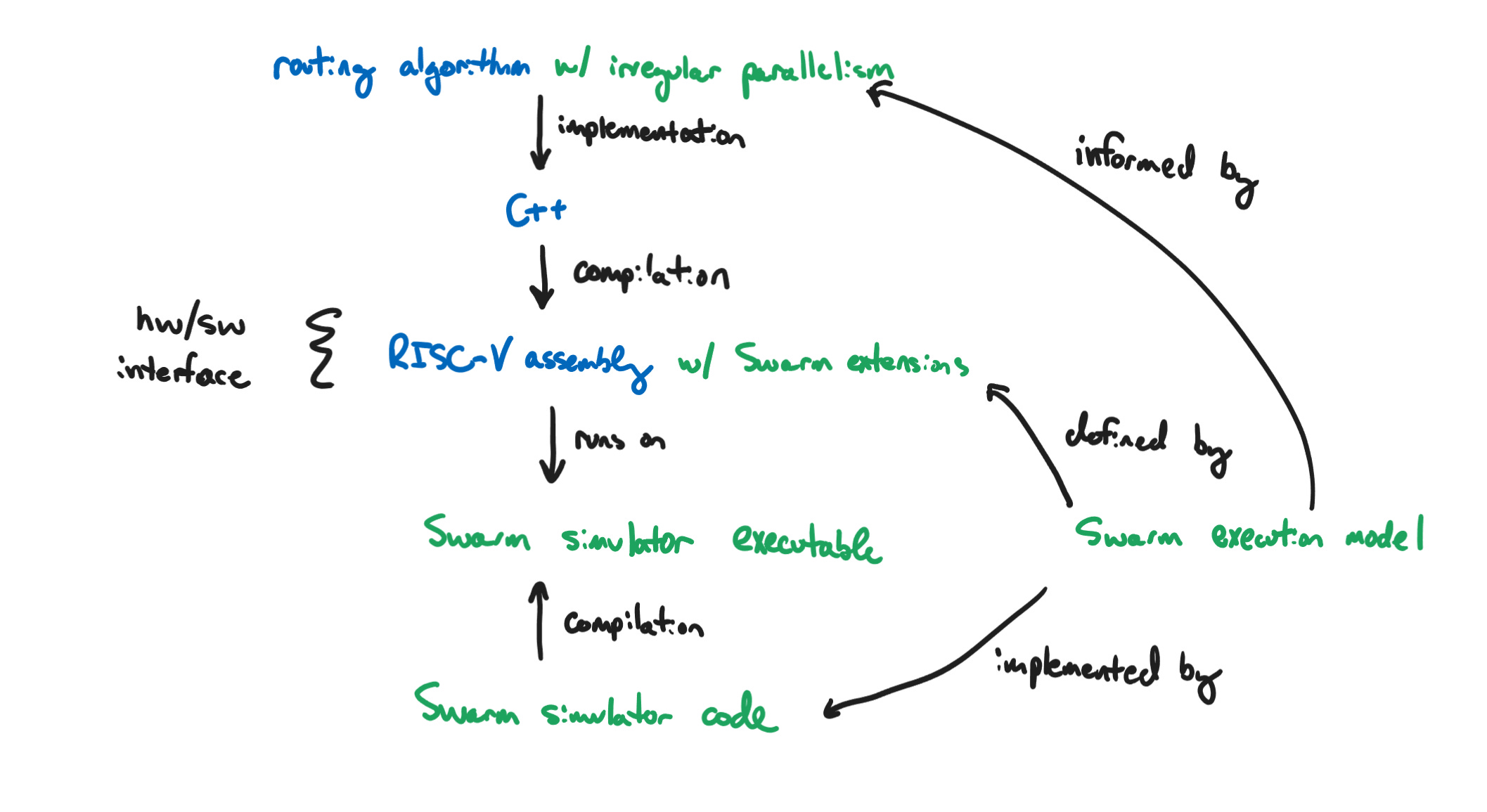
Just getting the Swarm binary to compile out of the VTR codebase was a difficult task. VTR is a codebase with a bunch of libraries which is typically only compiled for x64—I was compiling it for RISC-V—and bringing in random headers from Swarm didn’t help.3 For a few weeks, I got arcane compiler errors with strange C++ concepts like “virtual destructor was deleted in a union”4 in templated functions with absurdly long names and constant weird incompatibilities in the standard library, and I frankly did not understand what was going on. I kept pushing off the work for weeks on end because I just did not want to get my hands dirty or face the fear.
And then, eventually, I did it, and it was really not that bad. All I had to do was actually go and dig into the build system, reconnect a bunch of things, and then make some changes to types, and it was fine. Everything was fine, actually. The problem wasn’t the build system, or the C++ type system (though I have complaints); the problem was that I was unwilling to stop thinking at the level of my main task—“adapt the VTR algorithm to the Swarm execution model in basic C++”—to go and solve a problem at a lower level of the stack—“fix CMake and deal with function templates”—because that was a different level of abstraction I didn’t want to understand.
Once that was all up and running, and I was finally simulating the program in Swarm, I would occasionally get random errors, where the program would just terminate. Often, these would be segmentation faults, where for one reason or another I would have accidentally accessed memory that I hadn’t allocated, or had already freed. The first time this happened, all I got was a pointer into instruction memory—the address of the assembly instruction that had failed.
This, too, was frustrating, and it took me a few days to even find the binary that pointer was from, because Swarm has its own build system which generates a simulation binary by instrumenting a bunch of locations in the code, including every memory access. I then had to go in, dump the assembly of that binary using objdump, find the failing instruction, scroll up until I found the name of the function which would be another instruction pointer into the original RISC-V binary, and then figure out what C++ function that corresponded to and what was wrong with it.
If that sounds like nonsense to you, 1) I’m sorry, and 2) imagine trying to figure this out.
Whenever I got an error like this, I would spend what felt like a lot of time trying to avoid having to do this assembly gobbledygook. I desperately tried to cling to C++ land: I tried printing comments to figure out when the failure occurred, or undoing particular changes to figure out which of them caused the issue, or even serializing at different points to see if I could suss out what order of operations caused these bugs. But, inevitably, I would end up having to do this assembly digging, and less than an hour later, I would have my answer.
The point here is: the failure is not the complexity. We live in a complicated world which demands complicated systems, and to successfully navigate them, we need to be able to think at multiple levels of the stack. The thing that got in my way during the MEng (at least, on a technical level) was an unwillingness to bite the bullet and go one level deeper to solve the problem. It was the fear that I would lose the abstraction, when that was actually the best thing I could have done to make progress: to dive into the complexity and figure it out.
Now that I’ve spent half a year at Microsoft—boy, how the time flies—I’ve really come to appreciate how useful that lesson was. Very funnily, build systems and assembly are two of the things I’m still having to dive into. Even though the Windows build system is orders of magnitude more complicated than VTR’s—not to mention the testing infrastructure, or the human processes involved actually releasing updates—it hasn’t been too daunting to just dive in and figure things out as I need them. And, nowadays, I often debug code by just looking straight at the disassembly in our debugger—even though I have to parse both x64 and ARM64 assembly, which I didn’t explicitly learn at school.5
I’ve learned a bunch of new things, too, about interrupts, and drivers, and lots of long specifications with three- or four-letter acronyms; I’ve had to think very hard about synchronization and state machines and all that crazy jazz that makes systems programming what it is. I have a lot of more senior engineers I can ask questions—and they are extremely knowledgeable and helpful—but I also spend a lot of time just figuring things out on my own: searching and combing over documentation; reading code from people who are doing similar things and copying their patterns; following chains of function calls in the repository until I finally understand how this subsystem which my team doesn’t own works.
And it’s still scary, and confusing, and frustrating at times. But, more than anything, I feel great every time I do my digging and I just figure it out. Abstractions are useful—it is very hard to imagine that one could ever understand the entirety of the stack that runs any piece of software worth using, and in order to make forward progress, you need to stop digging somewhere, accept an interface, understand a data type by its operations. But you need to be willing to break them when they aren’t working; when there are questions to be answered, or things to be fixed.
Zooming out a little, I think this sentiment may be true of things in general. I think about my time conducting pit orchestras, and how much learning just a little bit about the keyboard programming or the parts of a drum kit has made me a vastly better orchestra director, even if I’m not an expert on any one of these things. Learning slightly more about lights, or sound, or directing has made me a more generally useful member of a directorial staff, even if I don’t spend time deep diving into each of those subjects. You could easily get lost in each of these fractal subworlds, which many people have dedicated their whole lives to—but the complexity alone is not a reason to not learn. Be not afraid.
Maybe this is my final attempt to reconcile the “jack of all trades, master of none” feeling I’ve always had about myself. I’ve always fancied myself spread a little too thin in my knowledge, cut across too many interests and hobbies, but maybe it’s not surprising that knowing a little bit about a lot can be really helpful, especially when it’s combined with knowing a lot about a little. A balance of the two, perhaps, to make a whole human person.
I tried multiple times to write a more technical explanation of what this meant, building up from terms which would be comprehensible to a generally educated layman, and failed miserably each time; it simply requires me to explain a little too much and would not allow me to get to the point of this post as quickly as I would like. But, this is a footnote, and, therefore, I am allowed to write as much as I want.
You can think of most circuits as implementing a kind of Boolean function; i.e., it takes a bunch of binary inputs (1s and 0s) and produces a bunch of binary outputs. For example, a very simple circuit might implement an AND gate—something that outputs 1 when both of its inputs are 1, and 0 otherwise. These circuits might also store some state (usually in registers), so that the outputs have some history—say, a counter that counts up every time its input is 1; that state is typically updated at the same time across the circuit, usually using a clock.
However, being able to describe a Boolean function is not equivalent to describing the actual hardware in the circuit. Say, for example, you are trying to implement an AND gate. Those might not be the actual pieces of hardware—what we’ll call “primitives”—you have to make the circuit. Instead, you might have to take the inputs and put them into a NAND gate (which does the opposite of an AND) and then a NOT gate to produce the same output.* Those actual pieces of hardware involved might also be different and have different characteristics, depending on what you’re using to make the circuit. Transforming the description of a circuit’s wires and behavior (usually written in a hardware description language, like Verilog) into a set of hardware primitives is called synthesis, and is generally a very difficult problem that involves optimizing for different objectives, such as area, power, or delay.
Once those primitives have all been synthesized, the difficulties of physical reality continue: these primitives need to be placed on a board, and the connections between them need to be routed—hence, place and route. Here, the details of the process diverge significantly between two kinds of hardware platforms—ASICs and FPGAs.
Circuits are often fabricated as application-specific integrated circuits (ASICs); i.e., actual pieces of silicon that directly implement the circuit initially described in HDL. An example of an ASIC is Google’s Tensor Processing Unit (TPU), which performs matrix operations which are important for its machine learning operations, like inference (TPU v1) and training (TPU v2). ASICs tend to be very fast and somewhat power-efficient, but they can be expensive to design and manufacture, and their function is fixed—once you have the actual chip in your hand, you can’t change whether that AND in your circuit was actually supposed to be an OR, and so on.
By contrast, field-programmable gate arrays (FPGAs) are hardware platforms that are reconfigurable. They do this by having an array of programmable hardware blocks and a network of wires that connect them. By having these wires pass through routing switches, the blocks can be connected to each other in different ways—essentially, physically rewiring the board—resulting in different outputs. Many of these blocks are also reconfigurable; for example, the most basic elements, configurable logic blocks (CLBs), contain lookup tables (LUTs) which take a fixed number of inputs and produce a configurable output, allowing them to implement simple Boolean functions. Circuits are synthesized to the particular elements which are present on the FPGA, which can be complex.**
Place and route is a very difficult problem, because you are solving a very complicated graph optimization problem with lots of constraints—you need to route tens or hundreds of thousands of signals to huge numbers of inputs across millions of wires, and you need to do it without ever sharing a wire between two signals, while also trying to minimize wire length and delay. For big circuits, it can take hours, if not days, to fully route an FPGA program. Furthermore, most implementations of FPGA routing are either serial and deterministic—meaning they run incredibly slowly but produce the same output every time—or parallel and non-deterministic, meaning they run (somewhat) faster on multiple cores, but don’t give you the same results every time, which is not of great use for “repeatability.”
One of the things that makes parallelizing routing hard is that it exhibits irregular parallelism (see footnote 2 for more details), which conventional CPUs struggle to handle. The crux of the thesis is that by using a different execution model—one built specifically to exploit this kind of irregular parallelism—we can still significantly improve the performance of routing without giving up determinism. In particular, we used the model of a hardware accelerator called Swarm, which breaks the problem down into tiny tasks which always appear to execute in order of a program-defined timestamp.
Swarm accomplishes this by secretly running the tasks out-of-order under the hood, and then selectively aborting tasks if it finds out that tasks made memory accesses which would appear to execute in the wrong order. For one example, say task A at timestamp 6 runs first and reads some value in memory. Then, task B at timestamp 5 runs and writes to that value in memory. This is a violation, because you would expect task A (which happens later) to read the value from task B. So, you have to abort task A, undoing whatever changes it made and running it again. By breaking the core routing algorithm of VTR (which is based on an old algorithm called Pathfinder) into small Swarm tasks, along with a number of other tricks, we got a 36x speed-up on our largest circuit.***
*This is a bit of a distraction, since we’re ultimately building up to FPGAs, but a fun fact. On most integrated circuits, this is likely, because CMOS transistors are inverting—for reasons we don’t have to get into right now, taking an input from low to high (0 to 1) for any CMOS-based gate can only drive the output lower (i.e., from 1 to 0, or stay the same).
**Modern FPGAs are loaded with all sorts of goodies—logic blocks that do specialized digital signal processing (DSPs), memories, even full ARM processors on some more recent ones.
***Of course, as this post is eventually going to argue, the devil is in the details with this kind of systems work. If you’re interested in knowing how that splitting of tasks is done, and what those “other tricks” are, I will direct you to the actual thesis, which this footnote should have done a decent job of preparing you for reading.
Imagine that you are a manager of a team of five, and you have five projects of the same size that need to be done: A, B, C, D, and E. If none of these projects depend on each other, then you’re free! You just assign one project to each worker, and life is golden. This is kind of task assignment might be referred to as “embarrassingly parallel.”
Now imagine that you know in advance, that project C depends on project B, and project E on project D. You have less parallelism available, certainly, but you can make the optimal scheduling decision in advance: do A, B, and D at once, and then C and E afterwards. This kind of task assignment, where dependencies are well-known in advance, exhibits “regular parallelism.”
Now, finally, imagine that you have no idea in advance what projects depend on each other, except that project A is first. Once you finish project A, you find out that you can now do projects B and C, but you don’t know whether B depends on C, or C depends on B, or neither. You can do both B and C at once, but if you do, you run the risk of having to stop C halfway through and starting it over, which will also cost some overhead. This is irregular parallelism.
A classic example of this is Dijkstra’s algorithm, which determines the shortest path to all points from a starting point. Serially, it does this by always visiting the closest node, and then finding the distance to all its neighbors. Say we have a graph like this:
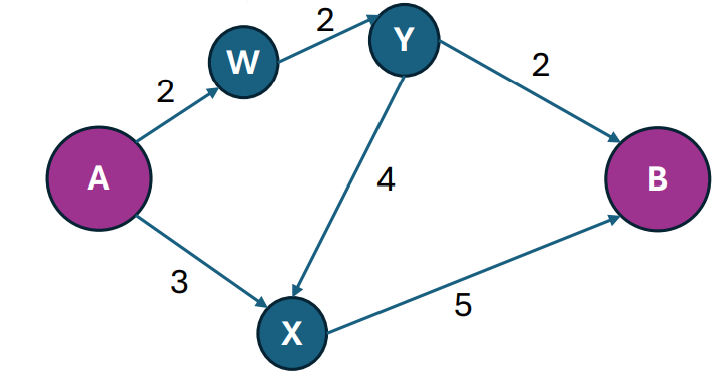
We can start by visiting A, from which we know that we can get to W in 2 steps, and X in 3 steps.
Because W is the closest node (at 2 steps) we haven’t visited yet, we visit it next, and we find that we can get to Y in 4 steps.
Then, we visit X (at 3 steps), and find we can get to B in 8 steps.
Then, we visit Y (at 4 steps), and find we can get to B in 6 steps.
Then, we visit B (at 6 steps).
But wait! After visiting A, we could totally visit W and X at the same time, and nobody would be any wiser. Let’s try that:
We start by visiting A, from which we know that we can get to W in 2 steps, and X in three steps.
We visit X (at 2 steps) and W (at 3 steps), from which we know that we can get to Y in 4 steps, and B in 8 steps.
At this point, though, we can’t visit B and Y at the same time, because that would set B’s distance to 8, and we know B’s actual distance is 6. So there is some parallelism here—we can visit X and W at the same time—but there are also dependencies—we can’t visit B until we visit Y.
We can exploit that parallelism while also avoiding dependencies by simply assuming there are no dependencies, and then rolling back our changes when we see one—an approach known as speculative execution. In this example,
We start by visiting A, from which we know that we can get to W in 2 steps, and X in three steps.
We visit X (at 2 steps) and W (at 3 steps), from which we know that we can get to Y in 4 steps, and B in 8 steps.
We visit Y (at 4 steps) and B (at 8 steps), from which we know that we can get to B in 6 steps.
We see that we can actually get to B in 6 steps, and we undo the visit queued from X, and visit B (at 6 steps) from Y instead.
This is a pretty toy example—but the approach does scale, with the right hardware setup; see the last two paragraphs of footnote 1, and, if you’re particularly curious, the 2015 Swarm paper.
RISC-V and x64 are both instruction sets architectures (ISAs), which define what basic operations your CPU can do (e.g., addi adds a constant to a register on RISC-V), among other things.* Code that is written in these basic operations (plus some very basic functionality, like labels) is typically called assembly. These operations are extremely basic, and so most software engineers write code in languages that are higher-level which are eventually compiled to assembly, or interpreted by a compiled interpreter. In any case, what’s running on your CPU is assembly instructions.**
RISC-V is open-source and commonly used on embedded systems; much of MIT’s coursework in lower-level systems uses RISC-V. Commercially available hardware, such as the computer or smartphone you’re reading this on, typically uses x64 (Intel, AMD; generally most Windows laptops, desktops) or ARM64 (some recent Windows laptops, smartphones, recent Macs***).
*These get increasingly arcane; we start with things like what state those operations can be on (registers, memory), to things like exception modes and page tables, and what memory instructions can be re-ordered across multiple processors and beyond. For example, the Intel x86-64 specification is large. I would tell you how large, but I don’t want to open it for fear of crashing my computer. Thousands of pages, certainly.
**Details of what’s running inside your CPU is beyond the scope of this footnote, but sometimes more complicated instructions are broken down into smaller ones through microops and microcode, which can sometimes go very wrong.
***Apple Silicon Macs aren’t full implementations of ARM, for reasons that are very complicated and involve scary phrases like “interrupt controller” or “ARM GIC”, which I will not explain in this already very-long blog post.
I still don’t really know what this one means, to be honest.
I’ve also learned some new tricks, like updating registers and rewriting assembly in memory while stopped in the debugger. This allows me to, say, force the code to take a certain branch, or avoid calling a certain function. Every time I do this, I feel incredible power.